When deploying an IPS appliance I saw a challenge that might come up if you are installing the IPS appliance in addition to a web proxy. One of the by-products of using the default settings of the proxy is that all user traffic going through the proxy ends up being NATted to the IP address of the proxy prior to going to the firewall. Normally this wouldn’t cause a problem but when you want to setup the IPS appliance to look at all traffic between the inside and firewall it presents an issue. We lose visibility into what the original client IP address is, all traffic appears as it is coming from one single IP address of the web proxy making IPS logs less useful. In an ideal situation you would be able to place the IPS in a position where it would examine the actual source IP address but not all networks may be able to accommodate this. One workaround is to utilize the x-forwarded-for header option on your proxy.
X-Forwarded-For Header
There is an industry standard(but not RFC) header available for HTTP called x-forwarded-for, that identifies the originating IP address of an HTTP request, regardless of if it goes through a proxy or load balancer. This header would typically be added by the proxy or load-balancer, but it’s worth noting that there are plugins out there that let a web browser insert this field(whether it is real or spoofed).
Current State
Our current state and traffic flow looks something like this:

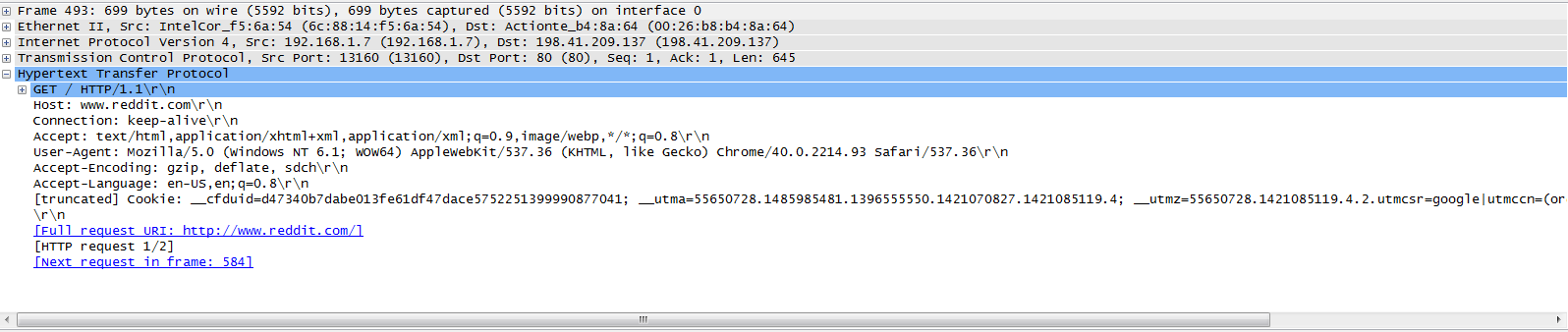
The IP starts as the original ‘real’ client IP, and as it goes through the proxy(websense in this case) it gets changed to the IP of websense. As it goes through the firewall it then gets changed to the IP of the firewall prior to hitting the Internet. Here’s a screenshot of a HTTP GET in wireshark, without any header:
Adding in the header
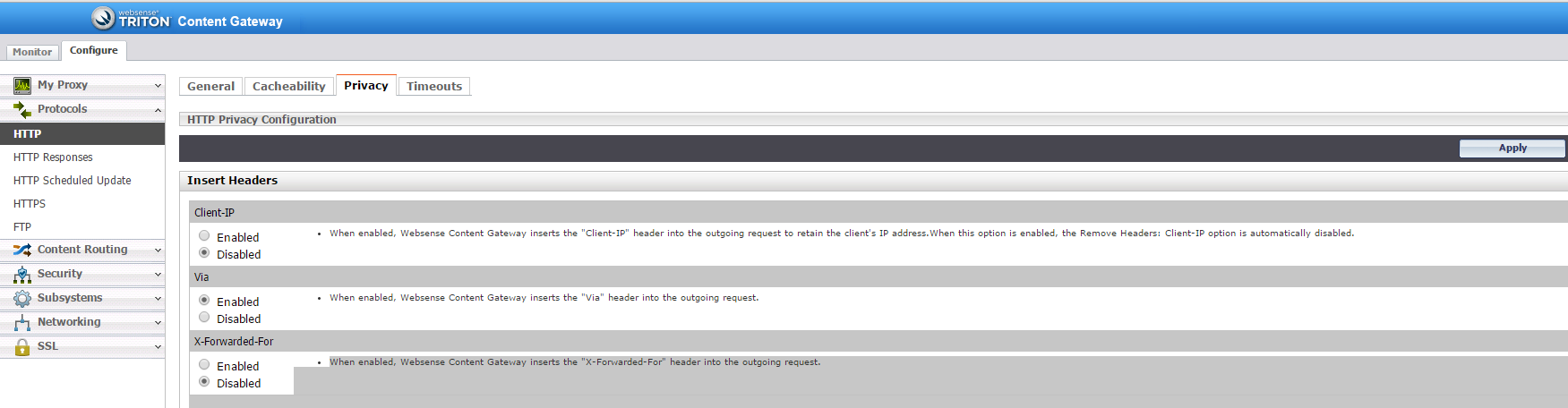
To add the header in Websense you can find the option here in the content gateway GUI:
X-Forwarded State
After enabling the addition of x-forwarded-for headers in Websense this is what our traffic looks like:

Here’s a screenshot of an HTTP GET in Wireshark that includes the header, spoofed to 1.2.3.4:

Inspection
Once this header is added it allows some IPS appliances/software to inspect the x-forwarded-for header and report on the actual client IP address. Snort currently supports this and there is more detail here. I believe that other IPS appliances such as Cisco’s Sourcefire also supports this option through enabling the HTTP inspect preprocessor and checking ‘Extract Original IP address’ option. Will work on confirming this and updating the post sometime soon. If you want to look at this traffic in wireshark there is a display filter ‘http.x_forwarded_for’ that will let you filter on x-forwarded-for.
Risks
I’d like to point out that the x-forwarded-for header gets carried in the packet out into the Internet which may or may not concern some people as it releases more information about your internal IP addresses structure than you might have wanted. I tried to see if there was an ASA feature to strip this header out but couldn’t find anything that looked like it fit besides this Cisco bug report/request for the feature. Also, as mentioned above you can spoof this header pretty easily, it is not authenticated or signed, and is presented in plain text. Each deployment will be unique and you’ll have to weigh out the risks and whether this is a feature that is worth implementing for your specific environment.












{kind=link}