I recently ran into an issue that was new to me, but after some further research proved to be fairly well known phenomenon that can be difficult to track down. We had a Cisco linecard with some servers connected to it that were generating a fairly large number of output drops on an interface, while at the same time having a low average traffic utilization. Enter the microburst.
Microbursts are patterns or spikes of traffic that take place in a relatively short time interval(generally sub-second) causing network interfaces to temporarily become oversubscribed and drop traffic. While bursty traffic is fairly common in networks and in most cases is handled by buffers, in some cases the spike in traffic is more than the buffer and interface can handle. In general, traffic will be more bursty on edge and aggregation links than on core links.
Admitting you have a problem
One of the biggest challenges of microbursts is that you may not even know they are occurring. Typical monitoring systems(Solarwinds,Cacti,etc) pull interface traffic statistics every one or five minutes by default. In most cases this gives you a good view into what is going on in your network on the interface level for any traffic patterns that are relatively consistent. Unfortunately this doesn’t allow you to see bursty traffic that occurs in any short time interval less than the one you are graphing.
Since it isn’t practical to change your monitoring systems to poll interfaces every second, the first place you might notice you are experiencing bursty traffic is in the interface statistics on your switch under “Total Output Drops”. In the output below, we are seeing output drops even though the 5 minute output rate is ~2.9Mbps (much less than the 10Mbps the interface supports).
Switch#sh int fa0/1 | include duplex|output drops|rate
Full-duplex, 10Mb/s, media type is 10/100BaseTX
Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 7228
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 2921000 bits/sec, 477 packets/sec
Output drops are caused by congested interfaces. If you are consistently seeing output drops increment in combination with reaching the line speed of the interface your best option is to look into increasing the speed of that link. In this case you would most likely see this high traffic utilization on a graph. If you are seeing output drops increment, but the overall traffic utilization of that interface is otherwise low, you are most likely experiencing some type of bursty traffic. One quick change you can make to the interface is to shorten the load interval from the default 5 minutes to 30 seconds using the interface-level command ‘load-interval 30’. This will change the statistics shown in the output above to report over a 30 second interval instead of 5 minutes and may make the bursty traffic easier to see. There’s a chance that even 30 seconds may be too long, and if that is the case we can use the Wireshark to look for these bursts.
Using Wireshark to identify the bursty traffic
I setup a simple test in the lab to show what this looks like in practice. I have a client and server connected to the same Cisco 2960 switch, with the client connected to a 100Mbps port and a server connected to a 10Mbps port. Horribly designed network, and most likely would not be seen in production, but will work to prove the point. The client is sending a consistent 3Mbps stream of traffic to the server using iperf for 5 minutes. Approximately 60 seconds into the test I start an additional iperf instance and send an additional 10 Mbps to the server for 1 second. For that 1 second interval the total traffic going to the server is ~13Mbps, greater than it’s max speed of 10Mbps.
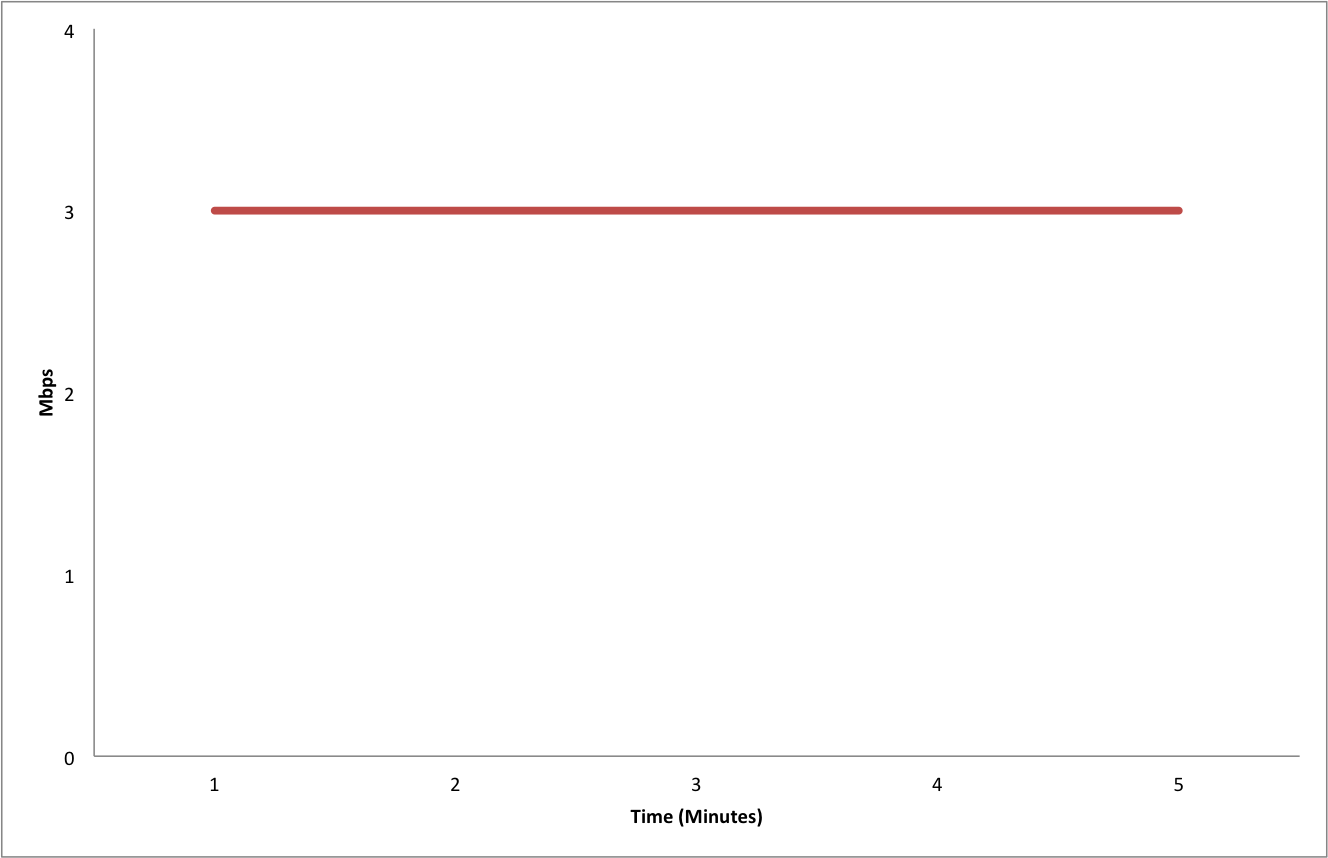
While running the tests I used SNMP to poll the interface every 1 minute to see what type of traffic speeds were being reported
From the graph you can see that it consistently shows ~ 3Mbps of traffic for the entire 5 minute test window. If you were recording data in 1 minute intervals with Solarwinds or Cacti, everything would appear fine with this interface. We don’t see the spike of traffic to 14Mbps that occurs at 1 minute.
I setup a span port on the server port and sent all the traffic to another port with a Wireshark laptop setup. Start your capture and let it run long enough to capture the suspected burst event (if the output drops seem to increase at the same time each day this may help you in narrowing in on the issue). Once your capture is done open it up in Wireshark. The feature we want to use is the “IO Graph”. You can get there via “Statistics” -> “IO Graph”
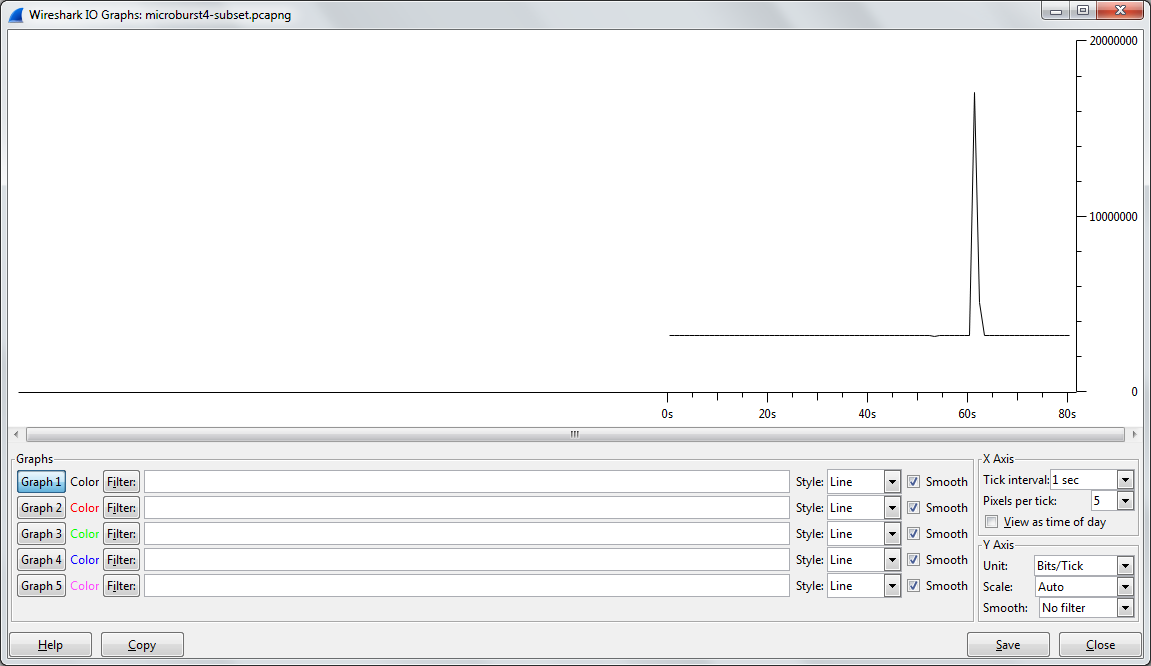
Wireshark IOGraph
Next we need to look at our X and Y Axis values. By default the X Axis is set to a “Tick Interval” of 1 second. In my case 1 second is a short enough interval to see the burst of traffic. If your spike in traffic is less then 1 second (millisecond for example), you may need to change the Tick Interval to something less than 1 second like .01 or .001 seconds. The shorter the time interval you choose, the more granular of a view you will have. Change the “Y-Axis” Unit from the default “Packets/Tick” to “Bits/Tick” because that is the unit the interface is reporting. It immediately becomes obvious on the graph that we do have a spike in traffic, right around the 60 second mark.

In my case the only traffic being sent was test iPerf traffic, but in a real network you would likely have a number of different hosts communicating. Wireshark will let you click on any point in the graph to view the corresponding packet in the capture If you click on the top of the spike in the graph, the main Wireshark window will jump to that packet. Once you identify the hosts causing the burst you can do some further research into what application(s) are causing the spike and continue your troubleshooting.
Conclusion
Identifying microbursts or any bursty traffic is a good example of why it’s important to ‘know what you don’t know’. If someone complains about seeing issues on a link it’s important not to immediately dismiss the complaint and do some due diligence. While monitoring interface statistics via SNMP in 1 or 5 minute intervals is an excellent start, it’s important to know that there may be things going on in the network that aren’t showing up in those graphs. By utilizing a number of different tools you can trace down problems. Reducing the interface load-interval to 30 seconds and tracking your output drops is a good start.Using Wireshark allows you to dive further into the problem and figure out what traffic is causing or contributing to the drops.